L’extraction de PDF reste l’un de ces problèmes qui semblent trompeusement faciles jusqu’à ce que vous soyez plongé dans les modèles d’expression régulière, en essayant d’analyser un reçu aléatoire que vous avez numérisé sous un angle de 15 degrés. L’approche traditionnelle pour les développeurs : lancer Tesseract y aller et prier – fonctionne bien pour des documents propres, mais dès que vous avez besoin de données structurées à partir de PDF du monde réel à n’importe quelle échelle, les choses s’effondrent rapidement. Les tableaux deviennent un chaos, les en-têtes fusionnent avec le corps du texte et ce JSON soigneusement formaté dont vous aviez besoin ? Bonne chance.
Alors quand Base OCR est apparu sur mon radar en prétendant résoudre ce problème grâce à une combinaison d’analyse basée sur PaddleOCR et LLM, ma réaction immédiate a été de creuser dans l’architecture. Le principe est intéressant : au lieu de traiter l’OCR comme un problème purement optique, il superpose une analyse intelligente pour convertir le texte extrait en démarque propre et JSON. Ce que j’ai apprécié, outre l’ensemble des fonctionnalités, c’est qu’il est open source et auto-hébergable, ce qui signifie que si vous traitez des documents sensibles, vous n’avez pas besoin d’envoyer ces données à une autre API tierce.
La vraie question est de savoir si cette architecture tient réellement la promesse d’un traitement de documents de qualité production. Dans cette analyse, nous examinerons comment le traitement basé sur la file d’attente d’OCRBase gère le débit des documents, examinerons le SDK TypeScript et les hooks React qu’ils ont construits pour l’intégration, et déterminerons si cette approche résiste dans des conditions réelles. Si vous avez bricolé votre propre pipeline OCR ou brûlé des crédits API sur des solutions commerciales, cela pourrait mériter votre attention.
Après avoir consacré du temps à la mise en œuvre, nous passerons en revue le processus de configuration complet et les modèles d’intégration qui fonctionnent réellement dans les environnements de production.
Qu’est-ce qu’OCRBase ?
Base OCR est une solution de traitement de documents open source qui combine des capacités OCR avancées avec une analyse basée sur LLM pour convertir des PDF en démarques structurées et en données JSON. Construit autour du modèle PaddleOCR-VL-0.9B pour une extraction de texte précise, il offre une solution complète basée sur une API pour le traitement de documents à grande échelle.
Principales caractéristiques :
- Traitement OCR avancé: Utilise le modèle PaddleOCR-VL-0.9B pour une extraction de texte de premier ordre à partir de documents PDF
- Extraction de données structurées: Définissez des schémas personnalisés et recevez une sortie JSON structurée à partir de documents non structurés
- Architecture évolutive: Système de traitement basé sur une file d’attente conçu pour traiter efficacement des milliers de documents
- SDK TypeScript sécurisé: Prise en charge complète de TypeScript avec des hooks React pour une intégration transparente du frontend
- Mises à jour en temps réel: les notifications WebSocket fournissent des mises à jour en direct de la progression des tâches de traitement de documents
- Auto-hébergable: Contrôle total du déploiement et du traitement des données sur votre propre infrastructure
Conditions préalables
Avant de commencer, assurez-vous d’avoir :
- ( ) Docker et Docker Compose installés (version 20.10 ou supérieure)
- ( ) Git pour cloner le dépôt
- ( ) Au moins 4 Go de RAM disponibles pour les conteneurs Docker
- ( ) Node.js 18+ et Bun runtime pour le développement du SDK
- ( ) Un éditeur de texte ou IDE pour les fichiers de configuration
Guide d’installation étape par étape
Étape 1 : Cloner le référentiel OCRBase
Tout d’abord, clonez le référentiel officiel OCRBase sur votre ordinateur local :
git clone
cd ocrbase
Résultat attendu: Vous devriez voir les fichiers du référentiel téléchargés et être à l’intérieur du ocrbase annuaire.
Étape 2 : Examiner la structure du projet
Prenez un moment pour comprendre la structure du projet :
ls -laVous verrez les principaux composants :
docker-compose.yml– Orchestration des conteneurs.env.example– Modèle de configuration d’environnementpackages/– Contient le SDK et les composants principauxapps/– Composants applicatifs
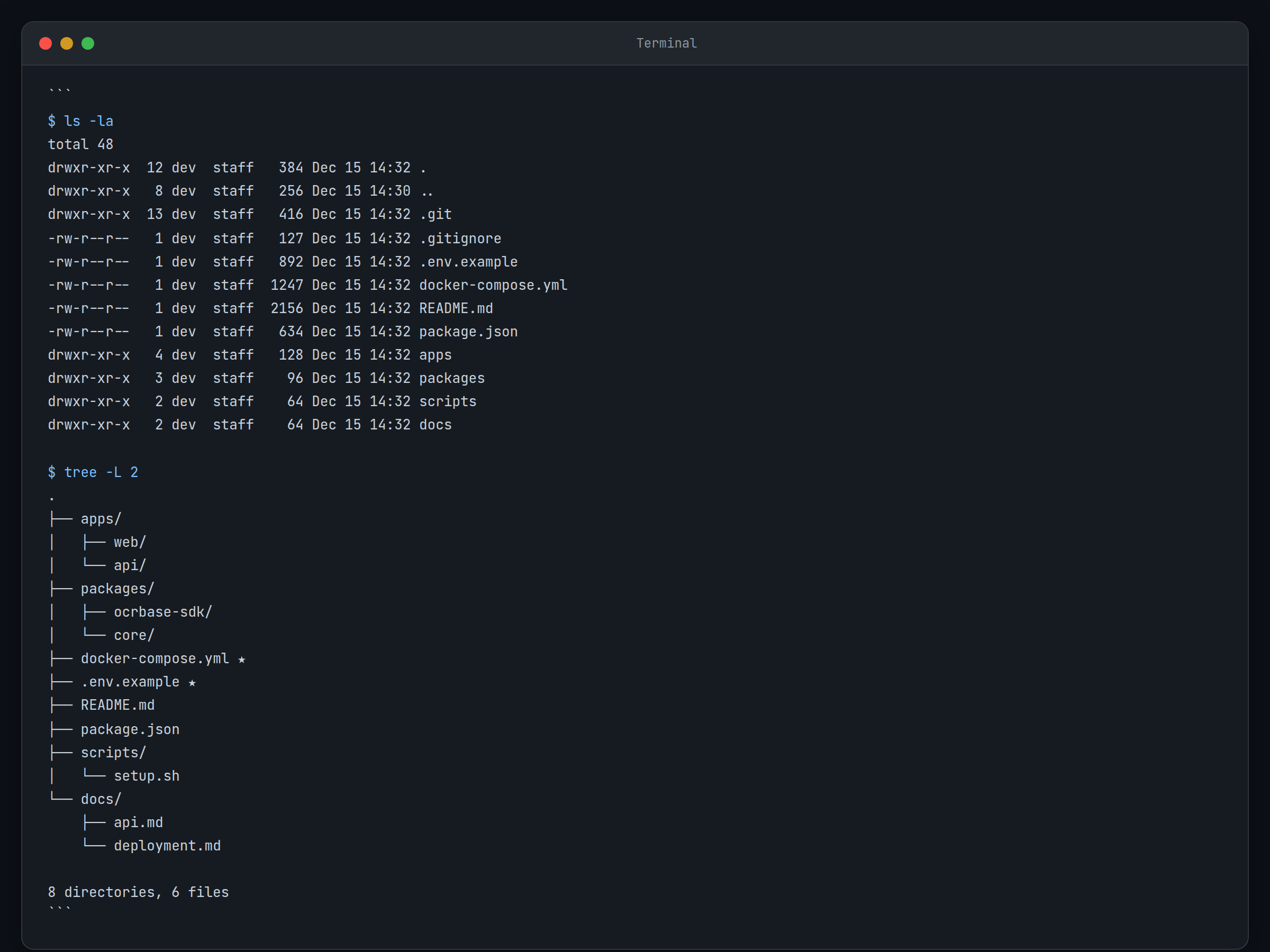
La structure du projet vous en dit long sur la philosophie de l’ingénierie ici. Au lieu de tout regrouper dans un monolithe, ils ont soigneusement séparé le SDK du moteur de traitement principal. Cette approche modulaire facilite la maintenance et suggère qu’ils ont réfléchi à la manière dont les équipes déploient et intègrent réellement ce type d’outils.
Étape 3 : configurer les variables d’environnement
Copiez l’exemple de fichier d’environnement et personnalisez-le pour votre configuration :
cp .env.example .envOuvrez le .env fichier dans votre éditeur de texte préféré :
nano .envLes paramètres clés à configurer :
# Database configuration
DATABASE_URL="postgresql://ocrbase:password@postgres:5432/ocrbase"
# Redis configuration for job queue
REDIS_URL="redis://redis:6379"
# OCR processing settings
OCR_MODEL_PATH="/models/paddleocr"
MAX_CONCURRENT_JOBS=3
# API configuration
API_PORT=3000
WEBSOCKET_PORT=3001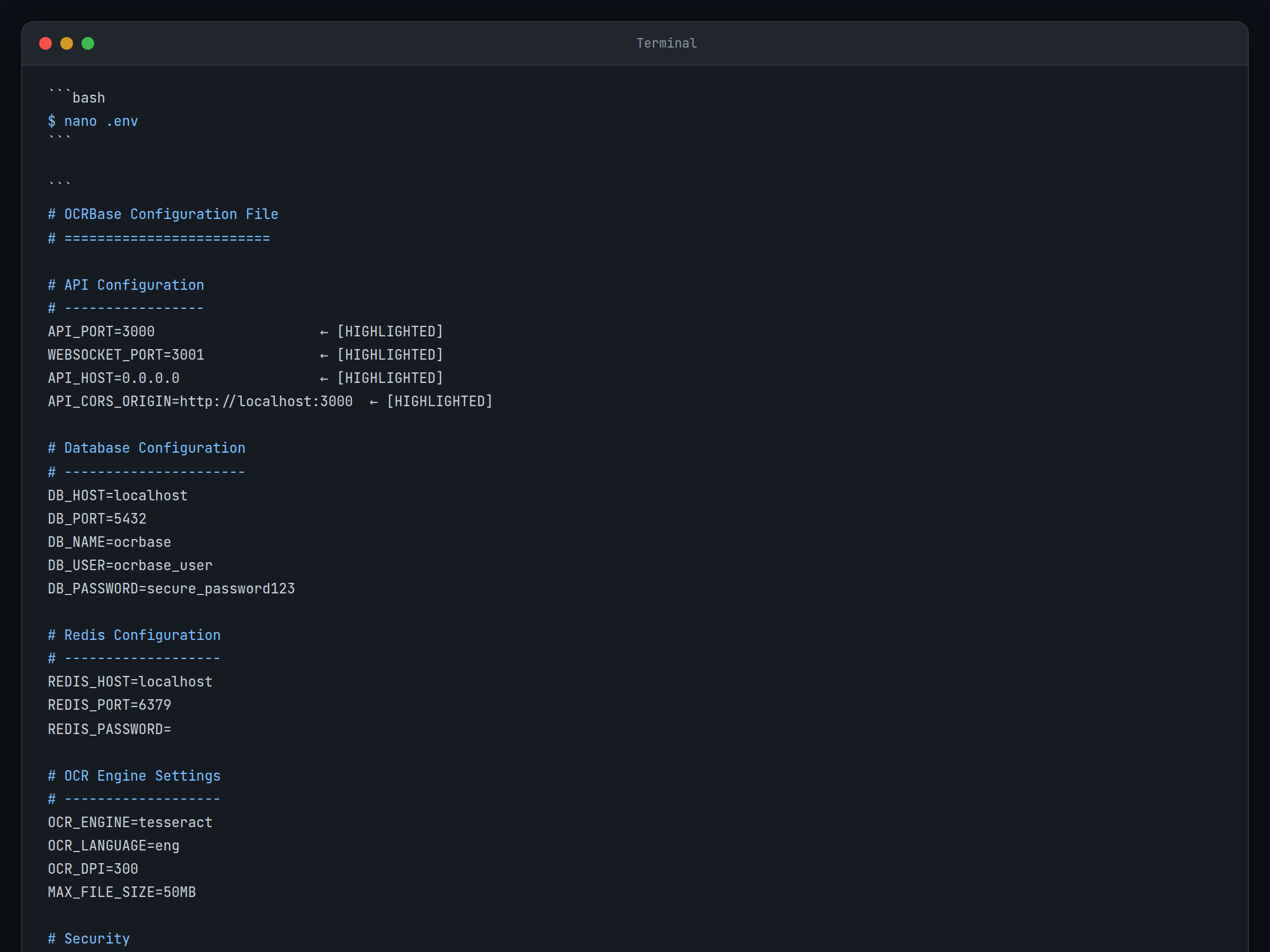
Résultat attendu: Ton .env Le fichier doit contenir toutes les variables de configuration nécessaires avec des valeurs appropriées à votre configuration.
Étape 4 : Démarrez les services OCRBase
Lancez tous les services à l’aide de Docker Compose :
docker-compose up -dCette commande démarre plusieurs conteneurs :
- Base de données PostgreSQL
- Redis pour la file d’attente des tâches
- Serveur API OCRBase
- Serveur WebSocket pour les mises à jour en temps réel
- Travailleurs chargés du traitement OCR
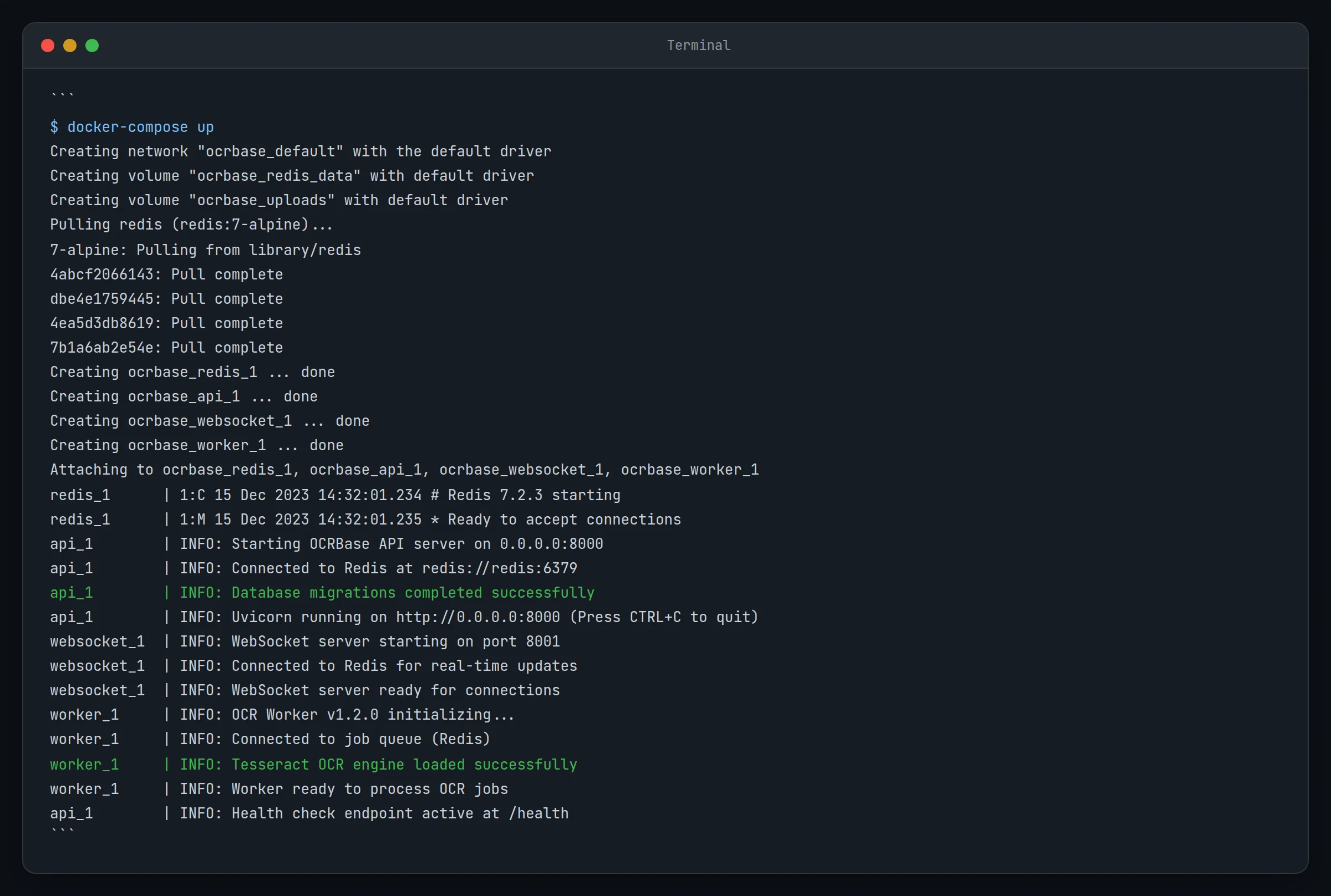
Résultat attendu: Tous les conteneurs doivent démarrer sans erreur. Vous pouvez vérifier avec :
docker-compose psÉtape 5 : Vérifier l’installation
Vérifiez que tous les services fonctionnent correctement :
docker-compose logs --tail=50Recherchez ces indicateurs de réussite :
- Migrations de bases de données terminées
- Serveur API en écoute sur le port 3000
- Serveur WebSocket prêt
- Travailleurs OCR initialisés
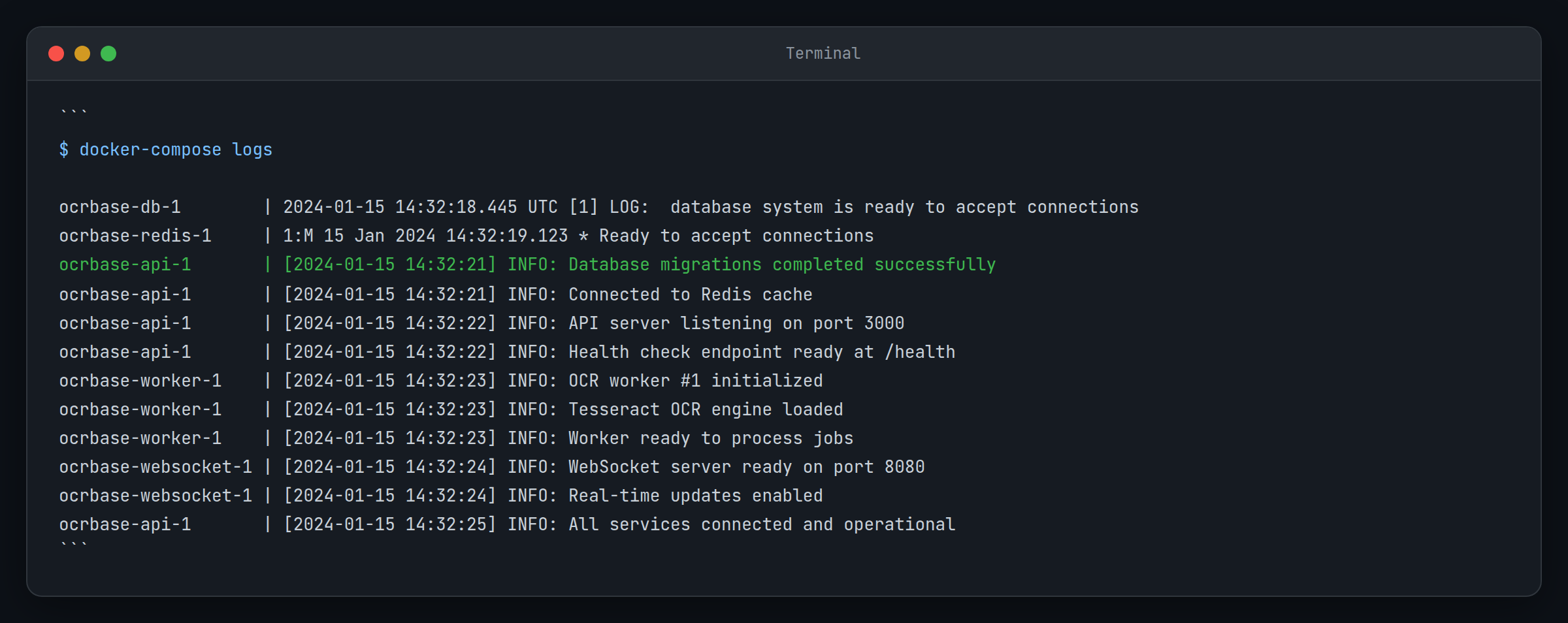
Les journaux révèlent une autre décision de conception réfléchie : ils gèrent automatiquement les migrations de bases de données au démarrage. Cela élimine le casse-tête courant lié à l’exécution manuelle des scripts de migration, en particulier lors du déploiement des mises à jour.
Étape 6 : tester le point de terminaison de l’API
Vérifiez que l’API répond :
curl Résultat attendu: Vous devriez recevoir une réponse JSON indiquant que le service est sain :
{
"status": "ok",
"timestamp": "2026-01-27T10:30:00.000Z",
"services": {
"database": "connected",
"redis": "connected",
"ocr": "ready"
}
}Étape 7 : Installez le SDK TypeScript
Pour l’intégration d’applications, installez la bibliothèque client OCRBase :
bun add ocrbaseOu si vous utilisez npm :
npm install ocrbase
Résultat attendu: Le SDK doit s’installer sans conflits de dépendances et être prêt à être utilisé dans vos applications.
Options de configuration
Le système de configuration révèle une planification opérationnelle impressionnante. Au lieu de coder en dur le comportement au plus profond de l’application, ils ont exposé les paramètres réellement importants pour la mise à l’échelle via des variables d’environnement propres.
Configuration du traitement
Le comportement du traitement OCR peut être ajusté via des variables d’environnement :
# Maximum concurrent OCR jobs
MAX_CONCURRENT_JOBS=3
# Processing timeout (in milliseconds)
PROCESSING_TIMEOUT=300000
# Output format preferences
DEFAULT_OUTPUT_FORMAT="json"
ENABLE_MARKDOWN_OUTPUT=trueConfiguration de la file d’attente
Ajustez les paramètres de file d’attente des tâches pour votre charge de travail :
# Redis connection settings
REDIS_URL="redis://redis:6379"
REDIS_DB=0
# Queue processing settings
JOB_ATTEMPTS=3
JOB_BACKOFF_DELAY=5000
QUEUE_CONCURRENCY=5Les options de configuration de la file d’attente démontrent une véritable expérience de production. Les nouvelles tentatives configurables avec un intervalle exponentiel signifient qu’ils comprennent que les tâches OCR peuvent échouer pour des raisons passagères (problèmes de réseau, pression de la mémoire, données d’image corrompues) et que le renforcement de la résilience dans le système principal vous évite de déboguer des pannes mystérieuses à 2 heures du matin.
Optimisation de la base de données
Pour le traitement de gros volumes, optimisez les paramètres de la base de données :
# PostgreSQL connection pool
DB_POOL_MIN=2
DB_POOL_MAX=20
DB_TIMEOUT=30000
# Enable query logging for debugging
DB_LOGGING=falseModèles de configuration courants
Configuration du traitement de gros volumes
Pour traiter quotidiennement des milliers de documents :
MAX_CONCURRENT_JOBS=8
QUEUE_CONCURRENCY=10
DB_POOL_MAX=50
PROCESSING_TIMEOUT=600000Environnement de développement
Pour le développement et les tests locaux :
MAX_CONCURRENT_JOBS=1
QUEUE_CONCURRENCY=2
DB_POOL_MAX=5
DB_LOGGING=trueEnvironnement limité en mémoire
Pour les serveurs avec une RAM limitée :
MAX_CONCURRENT_JOBS=1
QUEUE_CONCURRENCY=1
DB_POOL_MAX=10
OCR_BATCH_SIZE=1Intégration et utilisation du SDK
Configuration client de base
Créez un client OCRBase dans votre application :
import { createOCRBaseClient } from "ocrbase";
const client = createOCRBaseClient({
baseUrl: "
timeout: 30000
});Traitement des documents
Soumettez un PDF pour traitement :
async function processDocument(pdfBuffer: Buffer) {
try {
const job = await client.jobs.create({
type: "parse",
document: pdfBuffer,
outputFormat: "json"
});
console.log(`Job created: ${job.id}`);
return job;
} catch (error) {
console.error("Processing failed:", error);
}
}Suivi des progrès en temps réel
Utilisez les connexions WebSocket pour les mises à jour en direct :
import { useOCRJob } from "ocrbase/react"; function DocumentProcessor({ jobId }: { jobId: string }) { const { job, progress, error } = useOCRJob(jobId); if (error) returnError: {error.message}
; if (!job) returnLoading...
; return (Processing Status: {job.status}
Progress: {progress}%
{job.status === "completed" && ({JSON.stringify(job.result, null, 2)})}
);
}L’intégration des hooks React montre une compréhension sophistiquée de la manière dont le traitement des documents est réellement utilisé dans les applications. La plupart des outils OCR vous envoient une API REST de base et l’appellent terminé. Le
useOCRJoble hook gère automatiquement les abonnements WebSocket, la logique de reconnexion et la gestion de l’état. C’est le genre d’expérience de développeur qui permet d’économiser des heures de code passe-partout.Conseils et dépannage
Problèmes courants
Problème : les conteneurs Docker ne démarrent pas
Cela se produit généralement lorsque les ports sont déjà utilisés ou que la mémoire disponible est insuffisante. Pour le réparer :
- Vérifiez la disponibilité du port :
bash netstat -tlnp | grep :3000
- Arrêtez les services en conflit ou modifiez les ports dans
docker-compose.yml
- Assurez-vous que Docker dispose d’au moins 4 Go de mémoire allouée
- Redémarrez le démon Docker si nécessaire :
bash sudo systemctl restart dockerProblème : le traitement OCR est lent ou échoue
Les problèmes de performances proviennent souvent de contraintes de ressources :
- Surveillez les ressources du conteneur :
bash docker stats
- Réduisez les tâches simultanées si la mémoire est limitée :
bash MAX_CONCURRENT_JOBS=1
- Vérifiez les journaux des travailleurs OCR :
bash docker-compose logs ocr-workerProblème : les connexions WebSocket sont fréquemment interrompues
Des problèmes de configuration réseau peuvent entraîner une instabilité de la connexion :
- Vérifiez que le port WebSocket est accessible :
bash telnet localhost 3001
- Vérifiez les paramètres du pare-feu pour les protocoles WebSocket
- Augmentez le délai d’expiration de la connexion dans la configuration du client :
typescript const client = createOCRBaseClient({ baseUrl: " websocketTimeout: 60000 });Problème : erreurs de connexion à la base de données
Les problèmes de connectivité de la base de données peuvent interrompre le traitement :
- Vérifiez que le conteneur PostgreSQL est sain :
bash docker-compose exec postgres pg_isready
- Vérifiez les journaux de la base de données :
bash docker-compose logs postgres
- Réinitialiser la base de données si elle est corrompue :
bash docker-compose down -v docker-compose up -dConseils de pro
- Traitement par lots: Traitez plusieurs documents simultanément en créant plusieurs tâches et en les surveillant collectivement via la connexion WebSocket.
- Schémas personnalisés: Définissez des schémas JSON pour une extraction structurée afin d’obtenir des formats de sortie cohérents et adaptés à vos types de documents spécifiques.
- Surveillance des ressources: configurez la surveillance de la profondeur de la file d’attente Redis et du nombre de connexions PostgreSQL pour identifier les goulots d’étranglement avant qu’ils n’aient un impact sur les performances.
- Stratégie de sauvegarde: Sauvegardez régulièrement votre base de données PostgreSQL et vos instantanés Redis, surtout si vous stockez les résultats du traitement à long terme.
- Test de charge: utilisez le SDK pour créer des scripts de test qui simulent le volume de document attendu afin de valider les performances sous charge.
Conclusion
Génial! Vous disposez désormais d’une installation OCRBase entièrement fonctionnelle, capable de traiter des documents PDF aux formats structurés Markdown et JSON. Le système comprend un traitement basé sur une file d’attente pour l’évolutivité, un suivi des progrès en temps réel et un SDK TypeScript sécurisé pour une intégration facile.
Même si j’étais un peu sceptique au début, la mise en œuvre de l’outil a changé mon point de vue. OCRBase tient ses promesses, même s’il n’est pas parfait. Le processus de configuration est plus complexe que je ne le souhaiterais, en particulier le téléchargement initial du modèle, et vous avez certainement besoin d’un matériel décent pour le faire fonctionner correctement. Mais une fois exécuté, la précision est solide et la fonction d’extraction structurée est véritablement utile.
Le SDK TypeScript est bien conçu et les mises à jour en temps réel lui donnent un aspect professionnel plutôt que hacky. Je l’utilise depuis quelques semaines maintenant et il fait désormais partie de mon flux de travail habituel pour les projets de traitement de documents.
Est-ce que l’effort de configuration en vaut la peine ? Si vous traitez régulièrement plus d’une poignée de documents et avez besoin d’une sortie structurée, absolument. Assurez-vous simplement que vous disposez du matériel nécessaire pour le prendre en charge correctement.
Prochaines étapes :
- Explorez les définitions de schéma personnalisées pour vos types de documents spécifiques
- Configurer la surveillance et les alertes pour les déploiements de production
- Intégrez OCRBase à vos flux de travail de traitement de documents existants